前言
默认内存管理函数的不足
利用默认的内存管理操作符new/delete和函数malloc()/free()在堆上分配和释放内存会有一些额外的开销。
系统在接收到分配一定大小内存的请求时,首先查找内部维护的内存空闲块表,并且需要根据一定的算法(例如分配最先找到的不小于申请大小的内存块给请求者,或者分配最适于申请大小的内存块,或者分配最大空闲的内存块等)找到合适大小的空闲内存块。如果该空闲内存块过大,还需要切割成已分配的部分和较小的空闲块。然后系统更新内存空闲块表,完成一次内存分配。类似地,在释放内存时,系统把释放的内存块重新加入到空闲内存块表中。如果有可能的话,可以把相邻的空闲块合并成较大的空闲块。默认的内存管理函数还考虑到多线程的应用,需要在每次分配和释放内存时加锁,同样增加了开销。
可见,如果应用程序频繁地在堆上分配和释放内存,会导致性能的损失。并且会使系统中出现大量的内存碎片,降低内存的利用率。默认的分配和释放内存算法自然也考虑了性能,然而这些内存管理算法的通用版本为了应付更复杂、更广泛的情况,需要做更多的额外工作。而对于某一个具体的应用程序来说,适合自身特定的内存分配释放模式的自定义内存池可以获得更好的性能。
正文
一, 内存池的设计思想
- 先申请一块连续的内存空间,该段内存空间能够容纳一定数量的对象;
- 每个对象连同一个指向下一个对象的指针一起构成一个内存节点(node)。各个空闲的内存节点通过指针形成一个链表,链表的每一个内存节点都是一块可供分配的内存空间;
- 某个内存节点一旦分配出去,从空闲内存节点链表中去除;
- 一旦释放了某个内存节点的空间,又将该节点重新加入空闲内存节点链表;
- 如果一个内存块的所有内存节点分配完毕,若程序继续申请新的对象空间,则会再次申请一个内存块来容纳新的对象。新申请的内存块会加入内存块链表中。
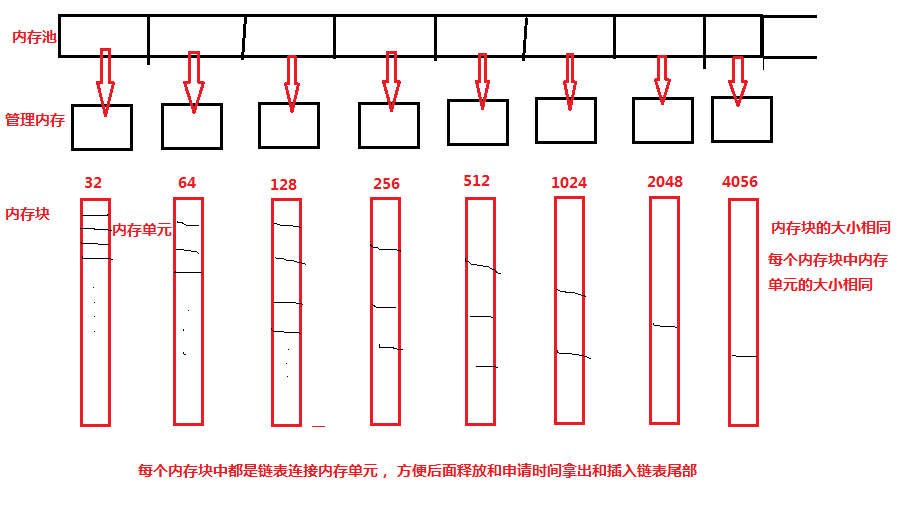
内存池的数据结构

二, 常见内存分配算法
1, 伙伴算法分配内存:
若申请的内存大小为n则将n向上取整为2的幂设次数为s,则需要分配s大小的内存块,定位大相应数组,
1.如果该数组有剩余内存块,则分配出去.
2.若没有剩余内存块就沿数组向上查找,然后再将该内存块分割出来s并将剩余的内存块放入相应大小的数组中.
例如分配5大小的内存块
———–>定位到大小为8的链表中
——–>若该链表中之中没有空余元素,则定位到16的链表中,16中有剩余元素,则取出该元素,并分割出大小为8的内存块供用户使用,然后将剩余的8连接到大小为8的数组中.
伙伴算法的内存合并:
当用户用完内存后会归还,然后根据该内存块实际大小(向上取整为2的幂)归入链表中,在归入之前,
- 我们还要检测他的伙伴内存块是否空闲,
- 如果空闲就合并在一起,合并后转到1,继续执行.
- 若果不是空闲的就直接归入链表中.
一般来说,伙伴算法实现中会用位图记录内存块是否被使用,用于伙伴内存的合并.
伙伴算法的特点: 显而易见,伙伴算法会浪费大量的内存,(如果需要大小为9的内存块必须分配大小为16的内存块).而优点也是明显的,分配和合并算法都很简单易行.但是,当分配和回收较快的时候,例如分配大小为9的内存块,此时分配16,然后又回收,即合并伙伴内存块,这样会造成不必要的cpu浪费,应该设置链表中内存块的低潮个数,即当链表中内存块个数小于某个值的时候,并不合并伙伴内存块,只要当高于低潮个数的时候才合并.
2, slab算法:
一般来说,伙伴算法的改进算法用于操作系统分配和回收内存,而且内存块的单位较大,利于Linux使用的伙伴算法以页为单位.对于小块内存的分配和回收,伙伴算法就显得有些得不偿失了.
对于小块内存,一般采用slab算法,或者叫做slab机制.
Linux 所使用的 slab 分配器的基础是 Jeff Bonwick 为SunOS操作系统首次引入的一种算法。Jeff的分配器是围绕对象缓存进行的。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。例如,如果内存被分配给了一个互斥锁,那么只需在为互斥锁首次分配内存时执行一次互斥锁初始化函数(mutex_init)即可。后续的内存分配不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。
Linux slab分配器使用了这种思想和其他一些思想来构建一个在空间和时间上都具有高效性的内存分配器。

图中给出了 slab结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在3 种 slab:
slabs_full:完全分配的slab
slabs_partial:部分分配的slab
slabs_empty:空slab,或者没有对象被分配
slab 列表中的每个slab都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab列表之间进行移动。例如,当一个 slab中的所有对象都被使用完时,就从slabs_partial 列表中移动到 slabs_full 列表中。当一个 slab完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中。
slab背后的动机
与传统的内存管理模式相比,slab缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
三, 我们要注意的问题
- 需要内存大于内存池中内存单元的处理
- 内存单元的利用率(内存单元使用频率相同) 3.