前言
C/C++程序在编译后指令
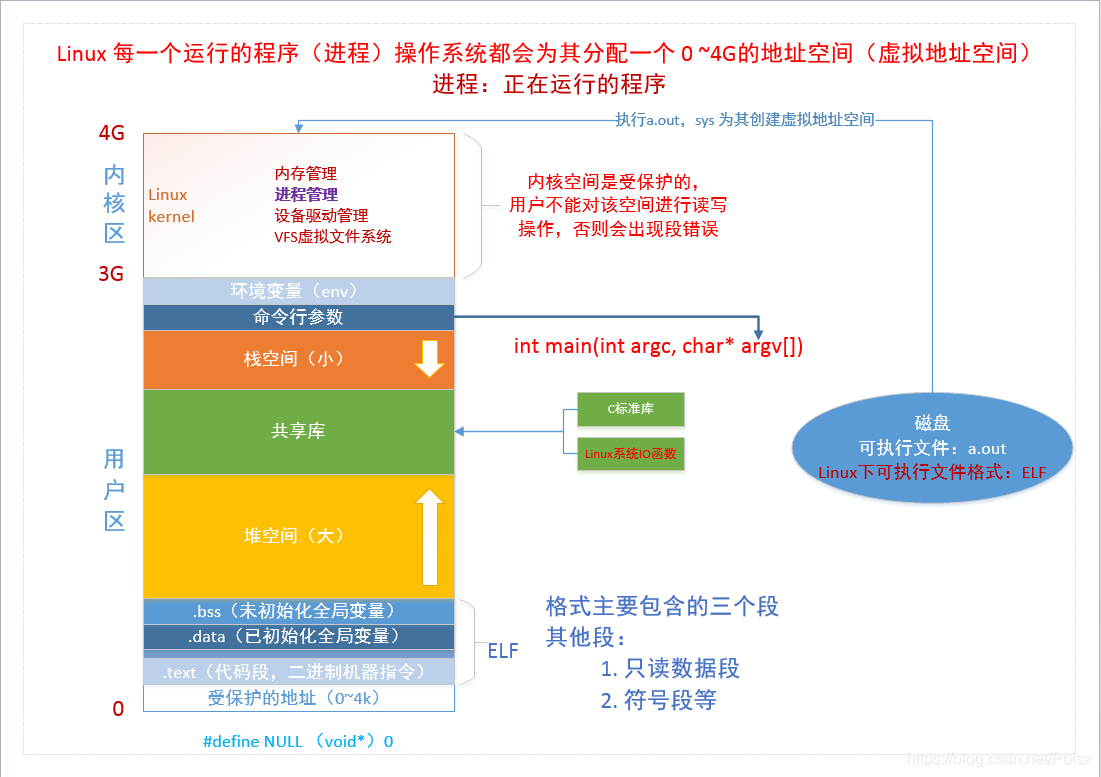
正文
一, 编译使用命令
1, 汇编命令
gcc -Og -S main.c
-
O0选项不进行任何优化,在这种情况下,编译器尽量的缩短编译消耗(时间,空间),此时,debug会产出和程序预期的结果。当程序运行被断点打断,此时程序内的各种声明是独立的,我们可以任意的给变量赋值,或者在函数体内把程序计数器指到其他语句,以及从源程序中精确地获取你期待的结果.
-
O1优化会消耗稍多的编译时间,它主要对代码的分支,常量以及表达式等进行优化。
-
O2会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。
-
O3在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
-
Os主要是对代码大小的优化,我们基本不用做更多的关心。
通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。
2, intel 汇编指令
gcc -Og -S -masm=intel main.c
3, 反编译 命令
objdump -d ${main}
二, 汇编指令
1, mov 指令的使用
C语言
void decode(long *xp, long *yp, long *zp)
{
long x = *xp;
long y = *yp;
long z = *zp;
*yp = x;
*zp = y;
*xp = z;
}
编译汇编
_Z6decodePlS_S_:
.LFB989:
.cfi_startproc
movq (%rdi), %r8
movq (%rsi), %rcx
movq (%rdx), %rax
movq %r8, (%rsi)
movq %rcx, (%rdx)
movq %rax, (%rdi)
ret
.cfi_endproc
.LFE989
2, 加载有效地址
指令leaq 实际上是movq的指令变形
long scale(long x, long y, long z)
{
long t = x + 4 * y + 12 * z;
//long t = 5 * x + 2 * y + 8 * z; // example
return t;
}
// x in %rdi, y in %rsi, z in %rdx
_Z5scalelll:
.LFB990:
.cfi_startproc
leaq (%rdi,%rsi,4), %rcx // x + 4 * y
leaq (%rdx,%rdx,2), %rax // z + 2 * z = 3 * z
leaq (%rax,%rdx,4), %rax // (x + 4 * y) + 4 * ( 3 * z) = x + 4 * y + 12 * z
//salq $2, %rax
//addq %rcx, %rax
ret
.cfi_endproc
// ----------------------example-------
//_Z5scalelll:
//.LFB990:
// .cfi_startproc
// leaq (%rdi,%rdi,4), %rax
// leaq (%rax,%rsi,2), %rax
// leaq (%rax,%rdx,8), %rax
// ret
// .cfi_endproc
3, 位操作
long arith(long x, long y, long z)
{
long t1 = x ^ y;
long t2 = z * 48;
long t3 = t1 & 0x0F0F0F0F;
long t4 = t2 - t3;
return t4;
}
// long arith (long x, long y, long z)
// x in %rdi , y in %rsi , z in %rdx
_Z5arithlll:
.LFB991:
.cfi_startproc
xorq %rsi, %rdi // t1 = x ^ y;
leaq (%rdx,%rdx,2), %rax // 3 * z;
salq $4, %rax // t2 = 16 * (3 * z) = 48 * z
andl $252645135, %edi // t3 = t1 & 0X0F0F0F0F;
subq %rdi, %rax // return t2 - t3
ret
.cfi_endproc
4, GDB 调试
常见的命令
| 命令 | 效果 |
|---|---|
| 开始和停止 | |
| quit | 退出GDB |
| run | 运行程序(在此给出命令行参数) |
| kill | 停止程序 |
| 断点 | |
| break multstore | 在函数mulstore入口处设置断点 |
| break * 0x400540 | 在地址0x400540处设置断点 |
| delete 1 | 删除 1 |
| delete | 删除所有断点 |
| 执行 | |
| stepi | 执行1条指令 |
| stepi 4 | 执行4条指令 |
| nexti | 类似于stepi, 但以函数调用为单位 |
| continue | 继续执行 |
| finish | 运行到当前函数返回 |
| 检查代码 | |
| disas | 反汇编当前函数 |
| disas multstore | 反汇编函数multstore |
| disas 0x400540 | 反汇编位于地址0x400540附近的函数 |
| disas 0x400540, 0x40043d | 反汇编指定地址范围内的代码 |
| print /x $rip | 以十六进制输出程序计数器的值 |
| 检查数据 | |
| print $rax | 以十进制输出%rax的内容 |
| print /x $rax | 以十六进制输出%rax的内容 |
| print /t $rax | 以二进制输出%rax的内容 |
| print 0x100 | 输出0x100的十进制表示 |
| print /x 555 | 输555 的十六进制表示 |
| print *(long *) 0x7fffffffe818 | 输出位于地址0x7fffffffe818的长整数 |
| print *(long *)($rsp + 8) | 输出位于地址$rsp + 8处的长整数 |
| x/2q 0x7fffffffe818 | 检查从地址0x7fffffffe818开始的双(8字节)字 |
| x/20bmultstore | 检查函数multstore的前20个字节 |
| 有用的信息 | |
| info frame | 有关当前栈帧的信息 |
| info registers | 所有寄存器的值 |
| help | 获取有关GDB的信息 |
5, 内存越界引用和缓冲区溢出
C/C++对于数组的引用不进行任何边界检查, 而且局部变量和状态信息(例如保存的寄存器值和返回地址)都存放在栈中。两种情况集合到一起就能导致严重的程序错误, 对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态
实例
char *getsl(char *s)
{
return s;
}
void echo()
{
char buf[8];
getsl(buf);
puts(buf);
}
_Z5getslPc:
.LFB993:
.cfi_startproc
movq %rdi, %rax
ret
.cfi_endproc
.LFE993:
.size _Z5getslPc, .-_Z5getslPc
.globl _Z4echov
.type _Z4echov, @function
_Z4echov:
.LFB994:
.cfi_startproc
subq $24, %rsp //alloc 24 stack
.cfi_def_cfa_offset 32
movq %rsp, %rdi
call puts
addq $24, %rsp //delete 24 stack
.cfi_def_cfa_offset 8
ret
.cfi_endproc
解释:
库函数gets的一个实现, 用来说明这个函数的严重问题,它从标准输入读入一行, 在遇到一个回车换行字符或某个错误情况时停止。它将这个字符串复制到参数s指明的位置, 并在字符串结尾加上null字符。在函数echo中我们使用gets这个函数只是简单地从标准输入中读取一行, 再把它回送到标准输出。
gets的问题是它没有办法确定是否为保护整个字符串分配了足够的空间。在echo实例中, 我们故意将缓冲区设置非常小–只有8个字节长。任何长度超过7个字符串都会导致写越界
gcc 优化编译生成保存的栈区
使用 -fno-stack-protector -Og 参数
g++ -S -fno-stack-protector main.cpp
_Z5getslPc:
.LFB977:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -8(%rbp)
movq -8(%rbp), %rax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE977:
.size _Z5getslPc, .-_Z5getslPc
.globl _Z4echov
.type _Z4echov, @function
_Z4echov:
.LFB978:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
leaq -16(%rbp), %rax
movq %rax, %rdi
call _Z5getslPc
leaq -16(%rbp), %rax
movq %rax, %rdi
call puts
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
结语
了解程序运行时栈上空间