创作历程 Creation Timeline
1. 技术路线图
从音视频、GPU 加速到大模型工程化,构建完整 AI 技术闭环。

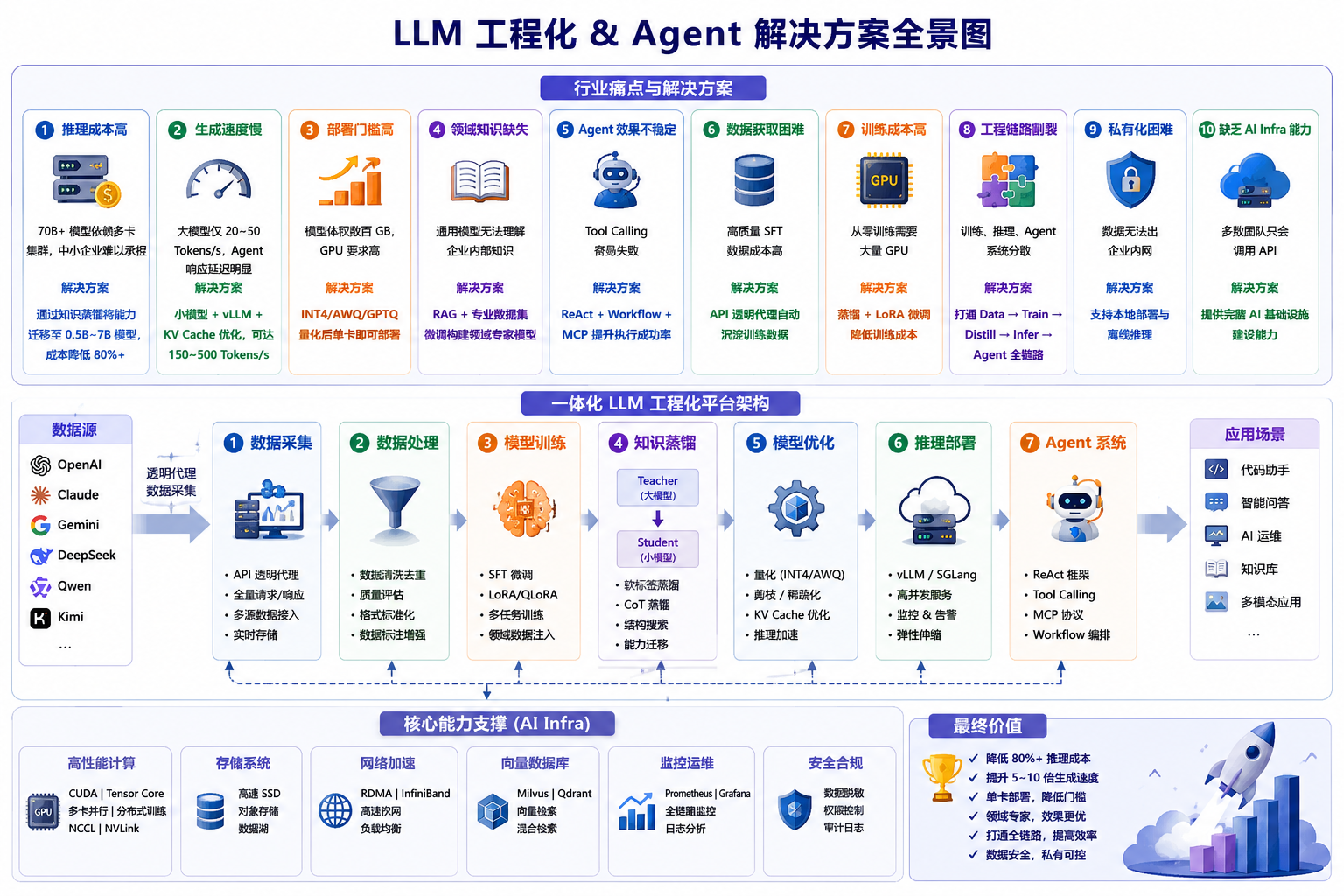
2. 业界痛点
| 痛点 | 行业现状 | 解决方案 |
|---|---|---|
| 推理成本高 | 70B+ 模型依赖多卡集群,中小企业难以承担 | 通过知识蒸馏将能力迁移至 0.5B~7B 模型,成本降低 80%+ |
| 生成速度慢 | 大模型仅 20~50 Tokens/s,Agent 响应延迟明显 | 小模型 + vLLM + KV Cache 优化,可达到 150~500 Tokens/s |
| 部署门槛高 | 模型体积数百 GB,GPU 要求高 | INT4/AWQ/GPTQ 量化后单卡即可部署 |
| 领域知识缺失 | 通用模型无法理解企业内部知识 | RAG + 专业数据集微调构建领域专家模型 |
| Agent 效果不稳定 | Tool Calling 容易失败 | ReAct + Workflow + MCP 提升执行成功率 |
| 数据获取困难 | 高质量 SFT 数据成本高 | API 透明代理自动沉淀训练数据 |
| 训练成本高 | 从零训练需要大量 GPU | 蒸馏 + LoRA 微调降低训练成本 |
| 工程链路割裂 | 训练、推理、Agent 系统分散 | 打通 Data → Train → Distill → Infer → Agent 全链路 |
| 私有化困难 | 数据无法出企业内网 | 支持本地部署与离线推理 |
| 缺乏 AI Infra 能力 | 多数团队只会调用 API | 提供完整 AI 基础设施建设能力 |
3. 技术方案
3.1 知识蒸馏 → 降成本
Teacher (70B+) → Student (0.5B ~ 14B)
推理成本降低 10~50 倍,消费级 GPU 可部署。
3.2 领域模型 → 补知识
结合 FFmpeg / WebRTC / 流媒体 / GPU 加速积累,训练:
AudioVideo-0.6B / 4B / 7B Agent 专项蒸馏模型
3.3 Agent 平台 → 建智能体

内容理解、智能处理、工具调用(FFmpeg / WebRTC / GPU 服务)自动协作。
3.4 推理优化 → 提速度
vLLM / TensorRT-LLM / SGLang · Continuous Batching · INT8/INT4 量化
提升 GPU 利用率与 Tokens/s,降低部署成本。
3.5 AI RTC → 落场景

AI 会议助手 · AI 客服 · AI 数字人
4. 项目路线图
| # | 项目 | 产出 |
|---|---|---|
| 1 | PolyDistill 知识蒸馏平台 | 通用蒸馏框架,多架构 Teacher→Student |
| 2 | 领域模型训练 | AudioVideo 系列、Agent 专项蒸馏模型 |
| 3 | 音视频 Agent 平台 | 感知→思考→行动闭环,工具调用编排 |
| 4 | 推理优化 & AI Infra | 量化模型、高并发推理、GPU 资源优化 |
| 5 | AI RTC | ASR+LLM+TTS+WebRTC 实时交互系统 |
5. 技术闭环

不追求最大模型,追求最低成本、最高效率、最易部署服务真实场景。

1. Technology Roadmap
From audio/video and GPU acceleration to LLM engineering — a complete AI technology closed loop.
2. Industry Pain Points
| Pain Point | Industry Status | Solution |
|---|---|---|
| High inference cost | 70B+ models rely on multi‑GPU clusters, unaffordable for SMEs | Transfer capabilities to 0.5B–7B models via knowledge distillation → cost reduced by 80%+ |
| Slow generation speed | Large models only 20–50 Tokens/s, noticeable Agent response latency | Small model + vLLM + KV Cache optimization → achieves 150–500 Tokens/s |
| High deployment barrier | Model size hundreds of GB, high GPU requirements | INT4 / AWQ / GPTQ quantization → single‑GPU deployment |
| Lack of domain knowledge | Generic models cannot understand enterprise internal knowledge | RAG + fine‑tuning on domain datasets → build domain expert model |
| Unstable Agent performance | Tool Calling often fails | ReAct + Workflow + MCP → improve execution success rate |
| Difficulty in data acquisition | High cost of high‑quality SFT data | API transparent proxy → automatically accumulate training data |
| High training cost | Full training requires massive GPU resources | Distillation + LoRA fine‑tuning → reduce training cost |
| Fragmented engineering pipeline | Training, inference, Agent systems are siloed | Unify the full pipeline: Data → Train → Distill → Infer → Agent |
| Difficulty in private deployment | Data cannot leave the corporate intranet | Support local deployment and offline inference |
| Lack of AI Infra capability | Most teams only know how to call APIs | Provide complete AI infrastructure building capability |
3. Technical Approach
3.1 Knowledge Distillation → Cut Cost
Teacher (70B+) → Student (0.5B ~ 14B)
Inference cost reduced 10~50×. Deployable on consumer GPUs.
3.2 Domain Models → Fill Knowledge Gaps
Leveraging FFmpeg / WebRTC / streaming / GPU acceleration expertise:
AudioVideo-0.6B / 4B / 7B Agent-specific distilled models
3.3 Agent Platform → Build Intelligence
Content understanding, intelligent processing, tool invocation (FFmpeg / WebRTC / GPU services).
3.4 Inference Optimization → Boost Speed
vLLM / TensorRT-LLM / SGLang · Continuous Batching · INT8/INT4 quantization
Higher GPU utilization & Tokens/s, lower deployment cost.
3.5 AI RTC → Real Applications
AI Meeting Assistant · AI Customer Service · AI Digital Human
4. Project Roadmap
| # | Project | Deliverables |
|---|---|---|
| 1 | PolyDistill Knowledge Distillation | Universal framework, multi-architecture Teacher→Student |
| 2 | Domain Model Training | AudioVideo series, Agent-specific distilled models |
| 3 | Audio/Video Agent Platform | Perception→Reasoning→Action loop, tool orchestration |
| 4 | Inference Optimization & AI Infra | Quantized models, high-concurrency, GPU optimization |
| 5 | AI RTC | ASR+LLM+TTS+WebRTC real-time interactive system |
5. Technology Closed Loop
Not the largest model — the lowest cost, highest efficiency, easiest deployment for real-world impact.