</font>
<hr style=” border:solid; width:100px; height:1px;” color=#000000 size=1”>
前言
2026年初,我开始用Agent写了好几个项目。当时本地部署了Google的开源模型Gemma-3-27B,写了一些程序,用的都是本地提示词。但总感觉比不上线上模型的“智商”——本地模型返回的规划之类的内容,说不出的别扭,对Agent的支持不咋地,ReAct也经常翻车。
尤其有一个项目clude_code项目AI编程助手,提示词我改了几十遍,稍微换一下输入说法,大模型输出的结果就出问题,特别折腾。
后来我尝试用一些领域数据做蒸馏,发现模型对Agent相关任务的支持开始慢慢变好了。于是我又做了透明代理截获全量请求/响应,落盘JSONL构建训练数据集(LLMInteractionRecorderProxy项目),用来收集线上大模型的请求数据。把这些数据加到自己的数据集里,再过滤清洗,然后在8B左右的小模型上做蒸馏。
效果还挺惊喜的——蒸馏出来的小模型,智能水平基本能赶上线上大模型。尤其是针对专业行业数据做了特征学习后,输出token速度非常丝滑,可以达到100 token/s以上。
所以我的体会是:AI Agent项目要真正落地,不能只靠调提示词。数据收集、知识蒸馏、领域模型、Agent框架、部署优化,这几样得捏在一起才有戏。
目前开源AI项目
1、透明代理截获全量请求/响应,落盘 JSONL 以构建训练数据集LLMInteractionRecorderProxy项目收集请求线上大模型的数据集 2、clude_code: 项目AI编程助手 3、PolyDistill:大模型知识蒸馏、小模型训练与推理优化工程实践 4、LLM 工程化 & Agent
1. 技术路线图
从音视频、GPU 加速到大模型工程化,构建完整 AI 技术闭环。

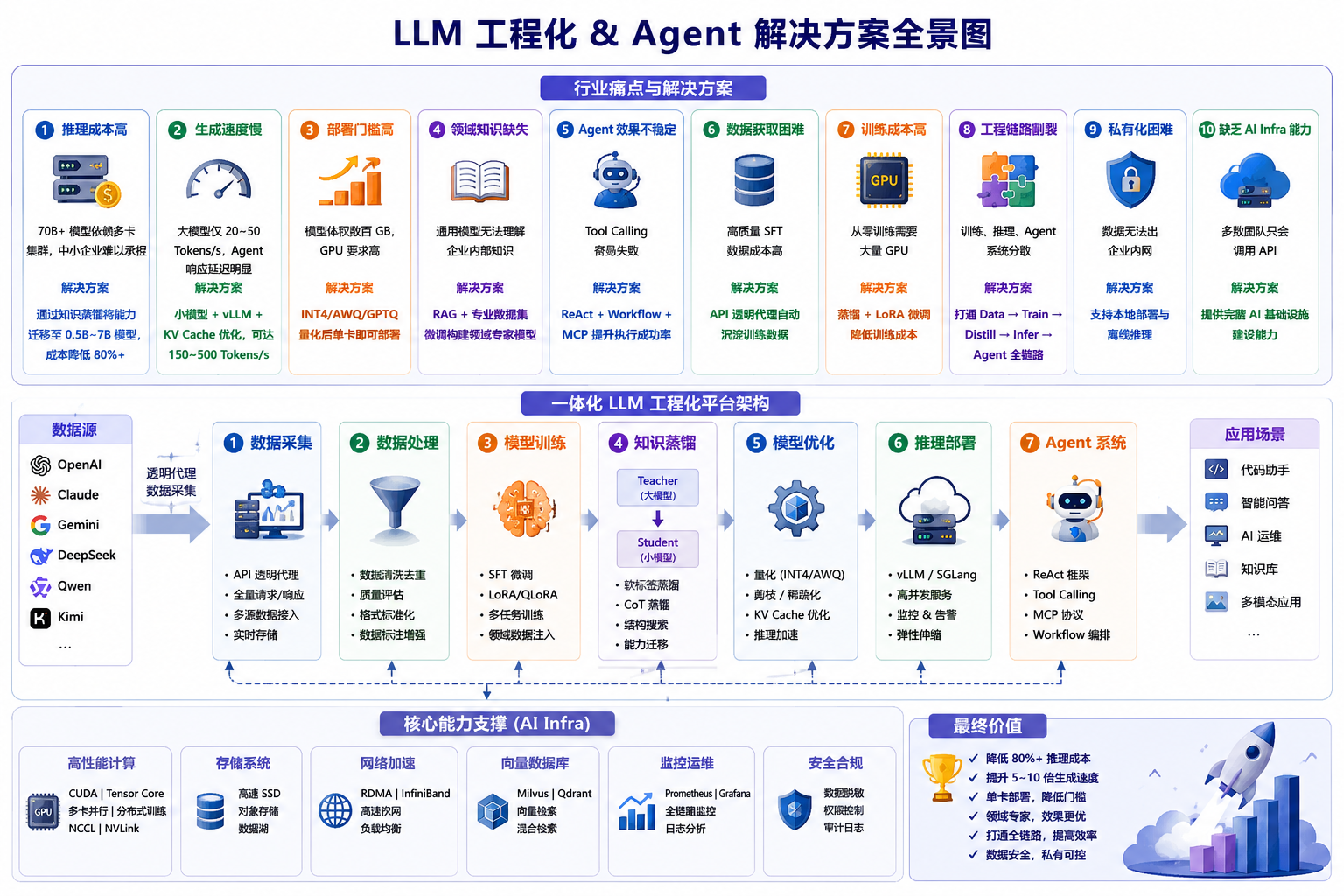
2. 业界痛点
| 痛点 | 行业现状 | 解决方案 |
|---|---|---|
| 推理成本高 | 70B+ 模型依赖多卡集群,中小企业难以承担 | 通过知识蒸馏将能力迁移至 0.5B~7B 模型,成本降低 80%+ |
| 生成速度慢 | 大模型仅 20~50 Tokens/s,Agent 响应延迟明显 | 小模型 + vLLM + KV Cache 优化,可达到 150~500 Tokens/s |
| 部署门槛高 | 模型体积数百 GB,GPU 要求高 | INT4/AWQ/GPTQ 量化后单卡即可部署 |
| 领域知识缺失 | 通用模型无法理解企业内部知识 | RAG + 专业数据集微调构建领域专家模型 |
| Agent 效果不稳定 | Tool Calling 容易失败 | ReAct + Workflow + MCP 提升执行成功率 |
| 数据获取困难 | 高质量 SFT 数据成本高 | API 透明代理自动沉淀训练数据 |
| 训练成本高 | 从零训练需要大量 GPU | 蒸馏 + LoRA 微调降低训练成本 |
| 工程链路割裂 | 训练、推理、Agent 系统分散 | 打通 Data → Train → Distill → Infer → Agent 全链路 |
| 私有化困难 | 数据无法出企业内网 | 支持本地部署与离线推理 |
| 缺乏 AI Infra 能力 | 多数团队只会调用 API | 提供完整 AI 基础设施建设能力 |
3. 技术方案
3.1 知识蒸馏 → 降成本
Teacher (70B+) → Student (0.5B ~ 14B)
推理成本降低 10~50 倍,消费级 GPU 可部署。
3.2 领域模型 → 补知识
结合 FFmpeg / WebRTC / 流媒体 / GPU 加速积累,训练:
AudioVideo-0.6B / 4B / 7B Agent 专项蒸馏模型
3.3 Agent 平台 → 建智能体

内容理解、智能处理、工具调用(FFmpeg / WebRTC / GPU 服务)自动协作。
3.4 推理优化 → 提速度
vLLM / TensorRT-LLM / SGLang · Continuous Batching · INT8/INT4 量化
提升 GPU 利用率与 Tokens/s,降低部署成本。
3.5 AI RTC → 落场景

AI 会议助手 · AI 客服 · AI 数字人
4. 项目路线图
| # | 项目 | 产出 |
|---|---|---|
| 1 | PolyDistill 知识蒸馏平台 | 通用蒸馏框架,多架构 Teacher→Student |
| 2 | 领域模型训练 | AudioVideo 系列、Agent 专项蒸馏模型 |
| 3 | 音视频 Agent 平台 | 感知→思考→行动闭环,工具调用编排 |
| 4 | 推理优化 & AI Infra | 量化模型、高并发推理、GPU 资源优化 |
| 5 | AI RTC | ASR+LLM+TTS+WebRTC 实时交互系统 |
5. 技术闭环

不追求最大模型,追求最低成本、最高效率、最易部署服务真实场景。
总结
LLM 工程化 & Agent (该项目是从 数据采集-> 知识蒸馏 -> 领域模型训练 -> 推理优化 -> Agent 平台 -> AI RTC 部署 整套技术闭环)