AI 工程师必备之八大 LLM 开发核心技能
@TOC
</font>
<hr style=” border:solid; width:100px; height:1px;” color=#000000 size=1”>
#
前言
最近在Google 出Gemini3.0 、马斯克团队出了Grok-4.1,OpenAI连夜出ChatGPT-5
- 2021年
- 人工智能(AI)向纵深发展
- “云”技术多样化发展
- 5G基站建设加速
-
2012年
-
深度学习元年
-
2017年
-
Google的Transfomer诞生
-
2022年
- 生成式AI技术为AIGC注入新动能,变革大众内容生产与交互范式
- 数字孪生技术应用于国际赛事制播,“虚拟预练”提升创作效能
- 虚拟制作技术应用提速,引领视听节目制作技术体系升级
- 数字人集成多维媒介要素,社会服务场景广泛拓展
- 3D数字建模高精度还原文化遗产,助力传统文化“数字永生”
- 超高清视频实现“经典重生”,社交推荐技术激活云演艺新场景
- 2023年(GPT3.5)
- 智能体热潮:人机交互新范式已被大模型打开
- 3D生成进入涌现期:新算法新模型爆发,质量效率可控性日新月异
- 分割模型大一统:计算机视觉即将迎来「ChatGPT时刻」
- 具身智能带来新想象:AGI终极场景下的全新终端
- 端到端自动驾驶成共识:BEV+Transformer重构技术路线
- 空间计算定义明确:消费级产品问世,XR全栈链路打通
- mRNA打开新象限:提供精准医疗新解法,开启生物医药新篇章
- 脑机接口试验新阶段:产品可靠性突破,AI提升数据解码能力
- 2024年
- 高性能计算的“四算聚变”
- 多模态智能体加速AGI进程
- AI加速人形机器人“手、脑”进化
- AI+基因计算解读生命密码
- 数字交互引擎激发超级数字场景
- 脑机接口从医疗突破迈向交互革命
- 沉浸式媒体催生3D在场
AI的前沿技术惊人的加快速进行落地(2021年OpenAI、2022年、2023年智能体磨牙期、2024年多模态Agent、2025年)、生产方式和获取知识方式都将迎来有史一次跨时代的变革(类似于工具时代进入蒸汽机时代)、2025年开始从头部企业开始技术人员(最明显是程序员,AI变革,以前程序员是脑力劳动、现在完全变化为苦力活)开始进行转到新AI时代生产工种、 未来可能将迎来一次重大失业潮, 原理是AI取代90%人的工作,但是新工种产生需要资本市场发展到AI产业链上而产生大批工种, 这个过程需要时间, 这个时间可能很快半年或者3年5年都有可能。
我们普通人只能跟踪时代发展,适应时代技术革命变化, 不停学习新的东西 ,想前领导在2023年让我玩一年数据集,我觉得没有意思,还是敲代码有意思。现在前沿技术看来是多愚蠢行为啊, 从现在前沿技术来看敲代码已经基本被淘汰了, 我嘛也没有办法开始探索新东西啦~~~
很多人以为使用大语言模型(LLM)只是“写提示词(prompting)”。但如果目标是打造生产级(production-grade)的 AI 系统,仅仅依赖提示词远远不够。
真正的 LLM 开发需要系统性的工程能力:模型如何设计、部署、优化与运维。
本文整理了 AI 工程师必须掌握的 8 项核心技能,它们构成了 LLM 应用开发的八大支柱。
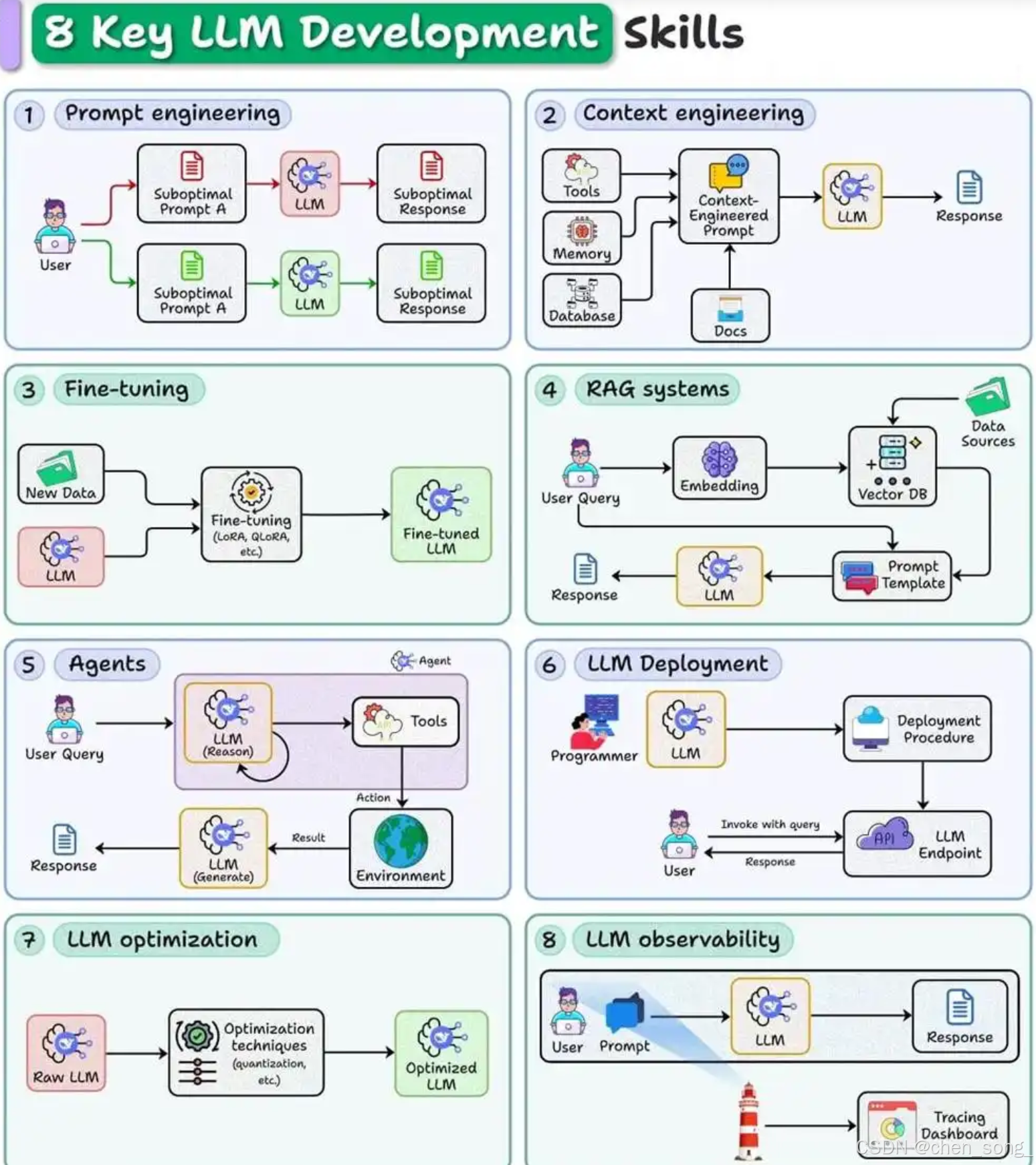
一、Prompt Engineering —— 提示词工程
这是 LLM 开发的入门技能
目标是 设计结构化的提示词,减少歧义,让模型输出更稳定、更可控。
-
快速迭代不同提示词版本
-
利用 Chain-of-Thought、Few-shot 示例等模式稳定回答
-
把提示词设计当作“可复现的工程任务”,而不是纯粹的“文案试错”
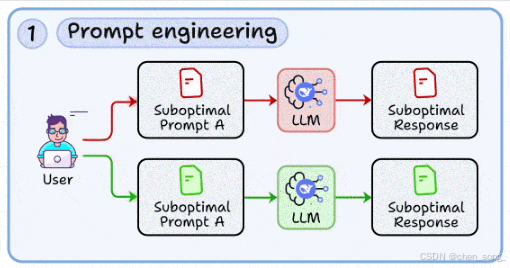
二、 Context Engineering —— 上下文工程
LLM 并不是无所不知,需要动态注入外部数据
-
从数据库、文档、工具结果、长期记忆中注入上下文
-
设计合理的上下文窗口,平衡信息完整性与 Token 成本
-
处理检索噪声与上下文塌缩,尤其在长上下文场景下
这项技能是 RAG 和智能体的基础。
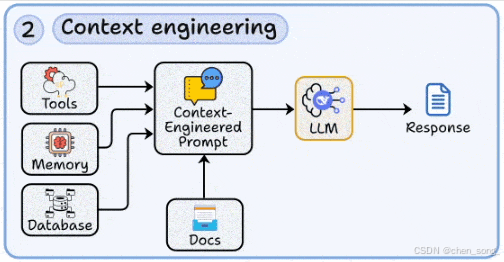
三、Fine-tuning —— 模型微调
当基础模型不能完全满足业务需求时,就需要微调
-
使用 LoRA / QLoRA 等高效方法,用领域数据适配模型
-
构建数据清洗与标注管道:去重、格式化、质量筛选
-
平衡“过拟合”与“泛化”,避免模型只记住训练样本
四、RAG 系统 —— 检索增强生成
RAG(Retrieval-Augmented Generation)是减少“幻觉”的关键技术
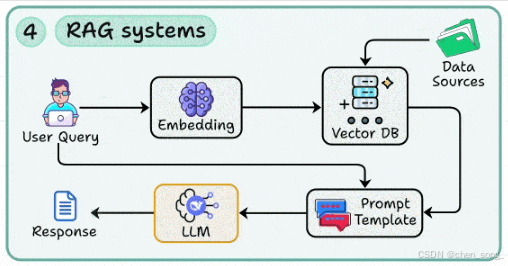
-
通过 向量数据库 + Embedding 检索外部知识
-
构建高召回率与高精度的检索管道(分块、索引、查询重写)
-
使用提示模板,把检索到的上下文和用户问题融合
这几乎是所有企业级 LLM 应用的标配能力
五、Agents —— 智能体
RAG 解决了知识增强,但要实现自主决策与复杂流程,需要 Agent 技术
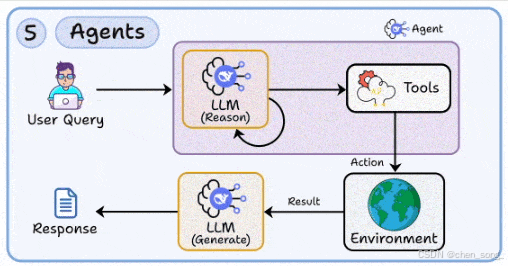
-
构建多步推理循环,驱动 LLM 使用工具完成任务
-
管理环境交互、状态流转、错误恢复
-
为推理失败或外部 API 出错设计回退机制
换句话说,Agent 让 LLM 从“聊天机器人”进化为“可行动的助手”
六、 LLM Deployment —— 模型部署
从原型到生产,部署是不可或缺的一步
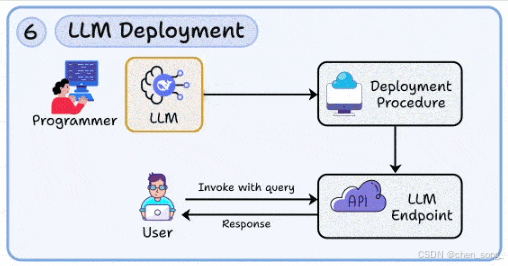
-
将模型打包为 可扩展的 API 服务
-
管理 延迟、并发、故障隔离(如自动扩缩容、容器编排)
-
增加安全与成本监控:请求审计、滥用防护、Token 成本追踪
像 Beam 这样的开源框架能加速部署流程
七、LLM Optimization —— 模型优化
生产中,性能与成本往往比参数量更重要
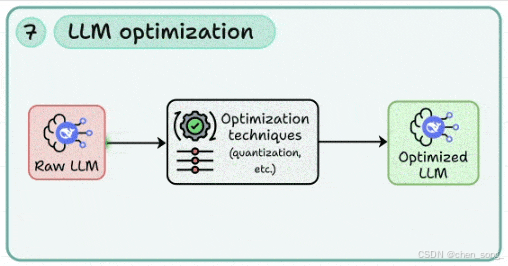
-
应用 量化(Quantization)、剪枝(Pruning)、蒸馏(Distillation)
-
在速度、准确率、硬件占用之间做权衡
-
持续进行性能分析,避免优化过度影响功能
优化是让 LLM 从“能跑”到“跑得快、跑得省”的必修课
八、LLM Observability —— 可观测性
没有监控的 AI 系统是不可控的
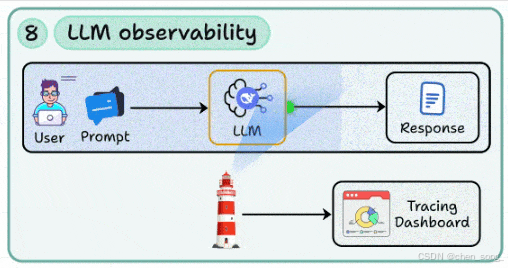
-
构建 日志、链路追踪、监控面板,追踪提示词与模型响应
-
监控 Token 消耗、延迟波动、提示词漂移
-
把观测数据反馈到开发迭代中,实现持续改进
这是 LLM 应用的“运维基石”。
如果说 Prompt Engineering 是 LLM 开发的起点,那么 上下文工程、RAG、Agent、微调、优化、部署与可观测性,才是把 LLM 真正带入生产的关键技能。
未来的 AI 工程师,不只是会写提示词,更要懂 AI + 系统工程 的全链路能力
总结
AI: https://chensongpoixs.github.io/#/