LLMSAPP
一、人工智能、机器学习、AIGC、深度学习和大模型关系图

正确的层次关系:
- AI(人工智能) - 最顶层,包含所有智能系统
- ML(机器学习) - AI 的子集,让机器从数据中学习
- DL(深度学习) - ML 的子集,使用神经网络
- LLM(大语言模型) - DL 的应用,特别是基于 Transformer 的模型
- AIGC(AI生成内容) - AI 的应用领域,通常使用 LLM 等技术


开源项目数据IE
二、 AI前沿技术
二、 大模型工具
Ollama是一个开源工具,旨在简化大型语言模型的本地化部署和使用,支持CPU/GPU混合计算,适用于隐私保护、成本控制等场景
三、 深度学习基本理论
四、深度神经网络训练参数优化篇
6、深度神经网络之全批量梯度下降、随机梯度下降和小批量梯度下降(mini-batch size)
8、深度神经网络之参数优化(BatchNormaliztion)
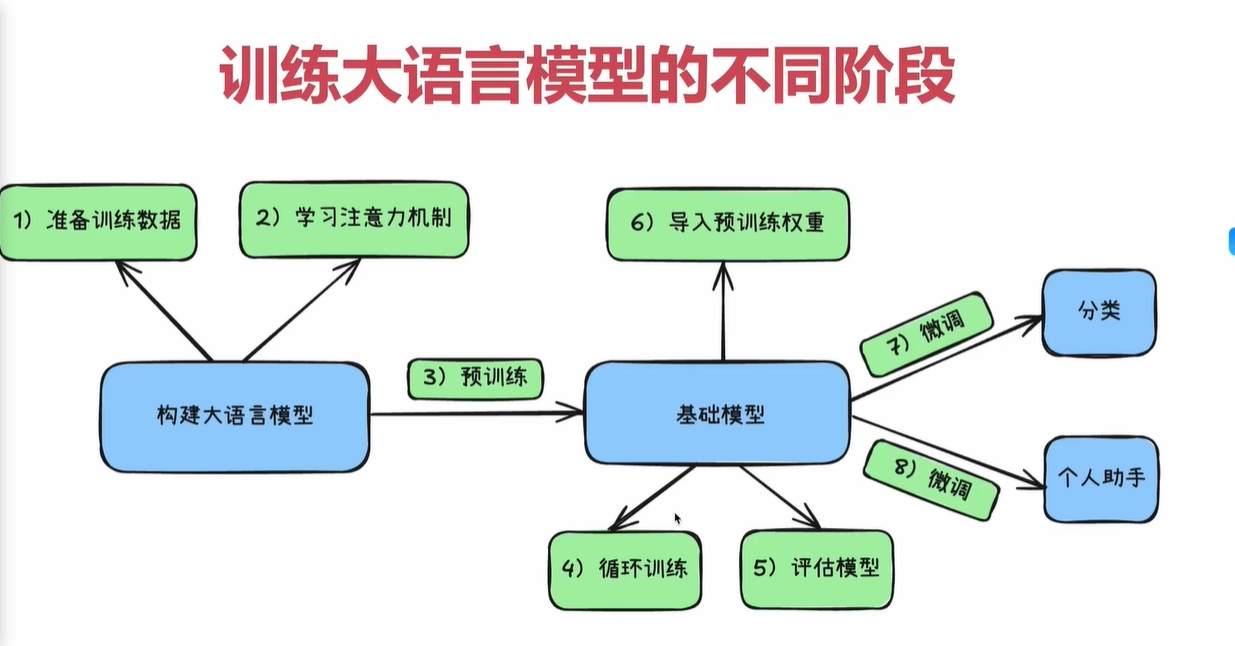
五、训练大语言模型的不同阶段
分为三大步
pip install jupyter
pip install matplotlib
1. 准备阶段

① 数据采集与初步处理
- 通过网络爬虫抓取数据
- 数据格式化, 将HTML转成纯文本
②、文本标准化与格式统一
- 统一编码, 全部转为utf-8格式
- 去掉各种HTML标签或JSON标识
- 处理特殊字符:乱码、表情符…
- 去掉多余的空格、空行
- 将所有大写字符转成小写字符(英文)
③、噪声去除与内容概率
- 删除重复数据
- 删除过短或者信息量不足的内容
- 过滤掉广告、导航、模板文本
- 过滤掉色情、暴力等信息
2. 预训练阶段

7. 交叉熵损失函数 torch.nn.funcational.cross_entropy(…)
3. 微调与应用